


ClickHouse 能夠支撐高性能資料查詢的核心秘密之一,就是其強大的儲存引擎 — MergeTree。這一篇將帶你深入理解 MergeTree 是什麼、它解決了哪些問題,以及如何透過不同的變種引擎 (ReplacingMergeTree, SummingMergeTree 等) 應對不同資料處理場景。
MergeTree 是什麼?
MergeTree 是 ClickHouse 中最基礎的儲存引擎,負責將大量寫入資料有效儲存與管理,並支援高效的查詢與資料合併(Merge)操作。
核心概念:
- 分區 (Partitions):將資料依據指定欄位(如日期)切分成不同區塊,減少查詢時需掃描的資料量。
- Primary Key (主鍵排序索引):定義資料在磁碟中的排序方式,讓查詢條件能快速定位資料範圍。
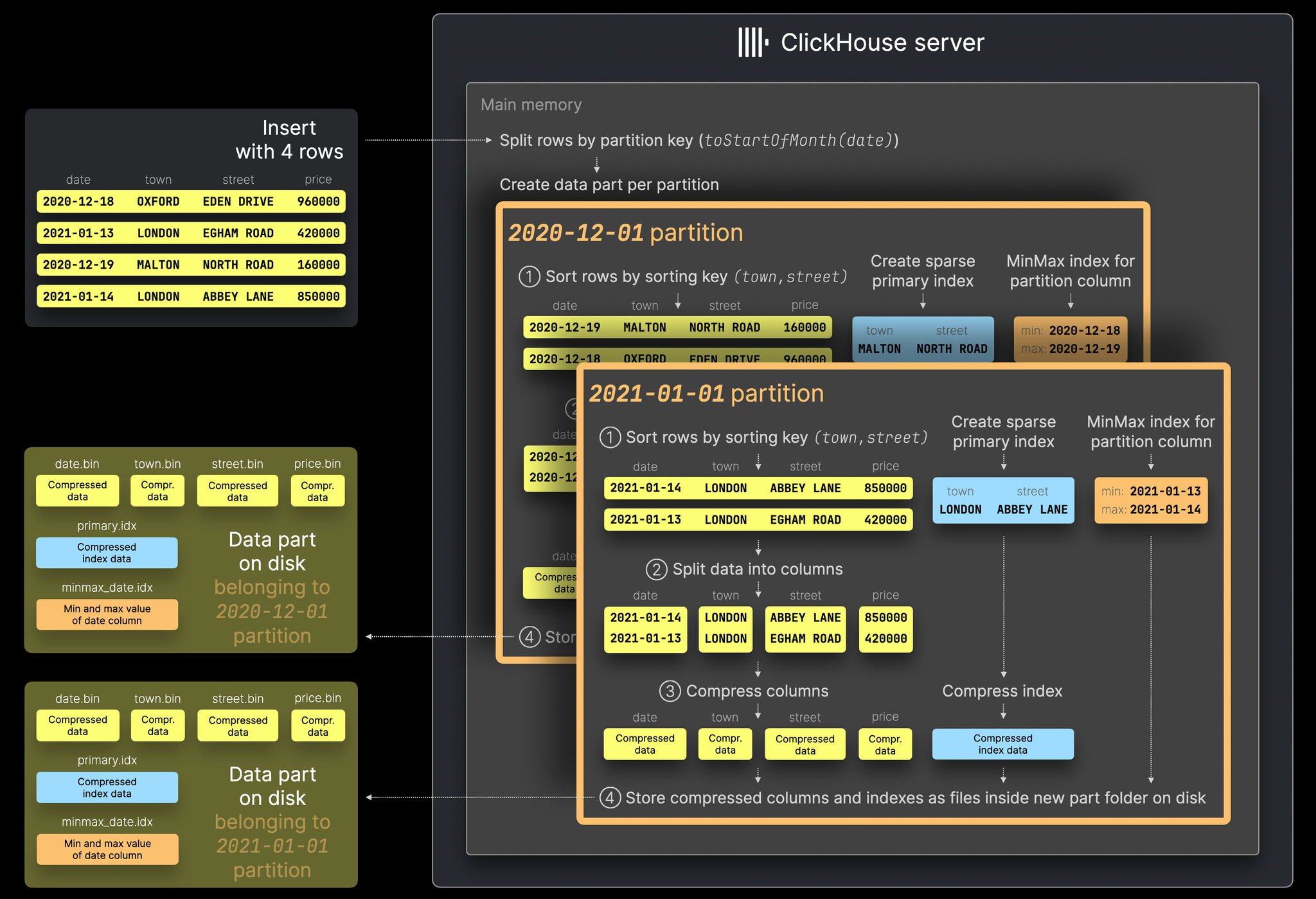
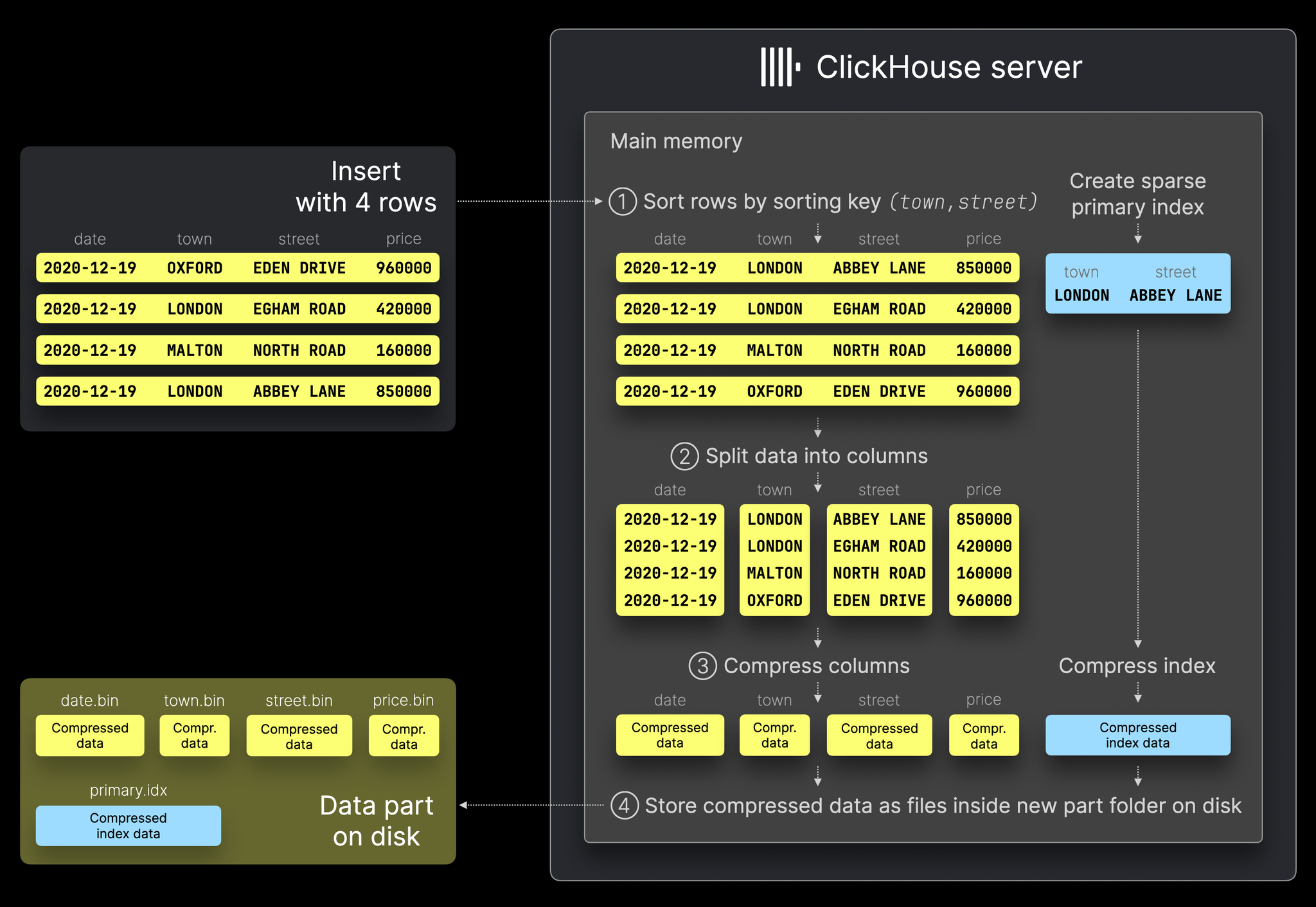
- Data Parts (資料片段):每次資料寫入時,都會生成一個 Data Part,經過以下手續:Sorting、Splitting、Compression,最後 Writing to Disk
NOTE
- Sorting:資料根據 Sorting Key(如 town, street)進行排序,並產生一個稀疏主鍵索引(Sparse Primary Index)。
- Splitting:排序後的資料會被拆分成單獨的欄位。
- Compression:每個欄位分別進行壓縮處理,應用 LZ4、ZSTD 等壓縮算法。
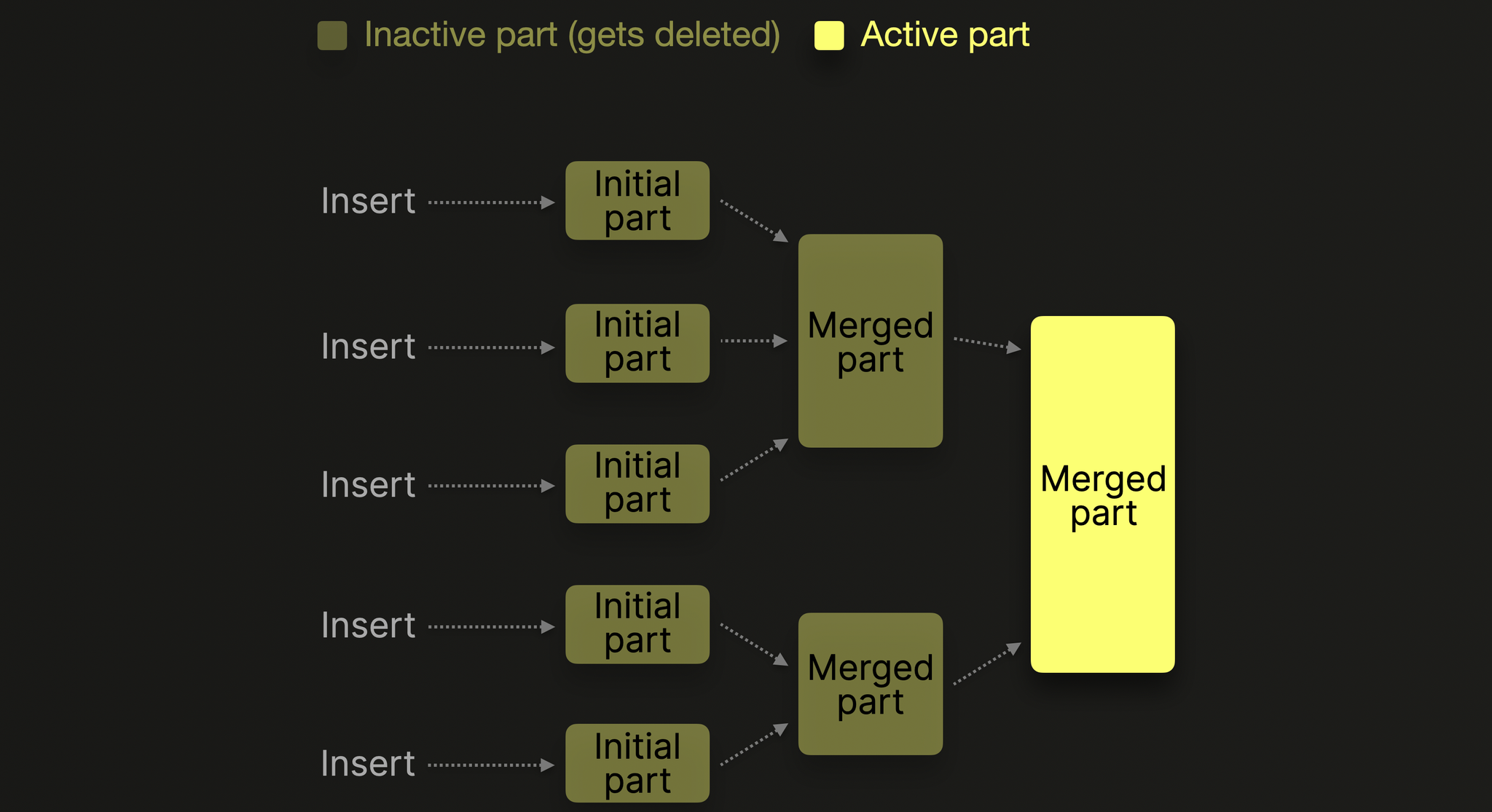
後續透過背景合併 (Merge) 將小片段整理成大型優化片段。
MergeTree 的核心特性與 Merge 操作原理
MergeTree 家族的引擎具備以下幾個特性:
-
Primary Key 排序與稀疏索引 (Sparse Primary Index):表格的主鍵決定了每個資料片段 (Data Part) 內的排序方式(Clustered Index)。不過,這個索引並不指向單筆資料,而是以 8192 筆資料為單位的 Granule (粒度)。這種設計讓主鍵索引即便在超大資料量下仍能被保留在記憶體中,並且能有效快速地存取磁碟上的資料區塊。
-
靈活的分區機制 (Partitioning):使用任意表達式來劃分分區,並能透過 Partition Pruning 技術在查詢時自動跳過不相關的分區,避免不必要的 I/O。
-
高可用性與容錯 (Replication):資料可於多個 Cluster Nodes 間進行複製,支援高可用性、故障切換 (Failover)、以及無停機升級 (Zero Downtime Upgrade)。
-
統計與抽樣查詢 (Sampling & Statistics):MergeTree 支援各類型的統計與抽樣機制,可協助查詢優化器進行查詢路徑選擇與加速。
MergeTree 解決了哪些問題?
- 大規模寫入效能瓶頸:透過將寫入資料分為小型 Data Parts 先行儲存,避免頻繁修改大型檔案帶來的 I/O 開銷。
- 查詢效率提升:依據 Partition 與 Primary Key 排序,能快速定位查詢資料區塊,避免全表掃描。
- 資料壓縮與去重整合:透過 Merge 操作合併資料時進行壓縮與去重,大幅降低儲存空間與查詢延遲。
語法和範例
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]( name1 [type1] [[NOT] NULL] [DEFAULT|MATERIALIZED|ALIAS|EPHEMERAL expr1] [COMMENT ...] [CODEC(codec1)] [STATISTICS(stat1)] [TTL expr1] [PRIMARY KEY] [SETTINGS (name = value, ...)], name2 [type2] [[NOT] NULL] [DEFAULT|MATERIALIZED|ALIAS|EPHEMERAL expr2] [COMMENT ...] [CODEC(codec2)] [STATISTICS(stat2)] [TTL expr2] [PRIMARY KEY] [SETTINGS (name = value, ...)], ... INDEX index_name1 expr1 TYPE type1(...) [GRANULARITY value1], INDEX index_name2 expr2 TYPE type2(...) [GRANULARITY value2], ... PROJECTION projection_name_1 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY]), PROJECTION projection_name_2 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY])) ENGINE = MergeTree()ORDER BY expr[PARTITION BY expr][PRIMARY KEY expr][SAMPLE BY expr][TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ] [WHERE conditions] [GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ][SETTINGS name = value, ...]建立 TABLE
CREATE TABLE user_events( EventDate Date, UserID UInt64, EventType String, EventValue Float32) ENGINE = MergeTree()PARTITION BY toYYYYMM(EventDate)ORDER BY (EventDate, UserID);寫入資料
INSERT INTO user_events VALUES ('2025-08-10', 1001, 'click', 1.0);INSERT INTO user_events VALUES ('2025-08-10', 1002, 'view', 1.0);INSERT INTO user_events VALUES ('2025-08-11', 1001, 'purchase', 299.99);查詢資料
SELECT *FROM user_eventsWHERE EventDate = '2025-08-10' AND UserID = 1001;此查詢會根據 Partition 先裁剪至 2025-08 分區,再透過 Primary Key (EventDate, UserID) 直接命中相關 Granule,大幅減少掃描資料量。
補充:指定索引 Granularity
若想更細緻控制 Primary Index 的粒度大小,可以透過 index_granularity 參數:
ENGINE = MergeTree()PARTITION BY toYYYYMM(EventDate)ORDER BY (EventDate, UserID)SETTINGS index_granularity = 8192;8192 是預設 Granule 大小,若資料查詢行為較分散,也可以調整為更小的粒度 (如 4096) 來提升查詢命中率,但會增加索引體積。
Granularity 會在後面的篇幅中詳細描述,由於這是額外補充,日後了解 Granularity 的定義和用途,可以再回來看補充~
MergeTree 家族的特殊變種
ClickHouse 根據不同業務需求,衍生出許多 MergeTree 變種引擎:
| 儲存引擎 | 特性與應用場景 |
|---|---|
| ReplacingMergeTree | 自動以指定欄位 (如 version 欄位) 替換重複資料,適合資料需去重的場景。 |
| SummingMergeTree | 在合併時自動將相同 Primary Key 的數值欄位進行加總,適用於資料匯總場景。 |
| AggregatingMergeTree | 針對 AggregateFunction 資料型別做更複雜的聚合運算,適合實時指標統計場景。 |
| CollapsingMergeTree | 透過 sign 欄位標記資料新增/刪除狀態,自動實現邏輯刪除與衝突解決。 |
| VersionedCollapsingMergeTree | 在 Collapsing 基礎上支援版本控制的資料去重。 |
Merge 操作的原理與效能影響
MergeTree 會在背景執行 Merge 操作,將多個小型 Data Part 合併成大型 Part,並在此過程中進行排序、壓縮與去重。
- Merge 頻率與效能平衡:Merge 操作會佔用系統 I/O 資源,設定合理的 Merge 參數(如
max_parts_to_merge_at_once)可平衡查詢與寫入效能。 - Mutation (資料變異操作):ClickHouse 也支援在 Merge 階段進行 UPDATE / DELETE 操作,但屬於非即時性處理,適合資料分析場景。
應用場景
- Log 分析:以日期為 Partition,URL 或 IP 為 Primary Key,支援快速查詢特定時段與條件的日誌資料。
- 使用者行為追蹤資料:透過
ReplacingMergeTree去重資料、SummingMergeTree快速整理使用者點擊行為。 - IoT 感測資料平台:大量寫入感測資料並以
AggregatingMergeTree實時統計各種資料指標。
結語
MergeTree 是 ClickHouse 高效能儲存與查詢的基礎,透過分區、排序與背景 Merge 機制,使得海量資料寫入與查詢皆能達到極致效能。針對不同業務場景選擇合適的 MergeTree 變種引擎,能夠很大的提升系統性能。
ClickHouse 系列持續更新中:
- ClickHouse 系列:ClickHouse 是什麼?與傳統 OLAP/OLTP 資料庫的差異
- ClickHouse 系列:ClickHouse 為什麼選擇 Column-based 儲存?講解 Row-based 與 Column-based 的核心差異
- ClickHouse 系列:ClickHouse 儲存引擎 - MergeTree
- ClickHouse 系列:壓縮技術與 Data Skipping Indexes 如何大幅加速查詢
- ClickHouse 系列:ReplacingMergeTree 與資料去重機制
- ClickHouse 系列:SummingMergeTree 進行資料彙總的應用場景
- ClickHouse 系列:Materialized Views 即時聚合查詢
- ClickHouse 系列:分區策略與 Partition Pruning 原理解析
- ClickHouse 系列:Primary Key、Sorting Key 與 Granule 索引運作原理
- ClickHouse 系列:CollapsingMergeTree 與邏輯刪除的最佳實踐
- ClickHouse 系列:VersionedCollapsingMergeTree 版本控制與資料衝突解決
- ClickHouse 系列:AggregatingMergeTree 實時指標統計的進階應用
- ClickHouse 系列:Distributed Table 與分布式查詢架構
- ClickHouse 系列:Replicated Tables 高可用性與零停機升級實作
- ClickHouse 系列:與 Kafka 整合打造即時 Data Streaming Pipeline
- ClickHouse 系列:批次匯入最佳實踐 (CSV、Parquet、Native Format)
- ClickHouse 系列:ClickHouse 與外部資料源整合(PostgreSQL)
- ClickHouse 系列:如何提升查詢優化?system.query_log 與 EXPLAIN 用法
- ClickHouse 系列:Projections 進階查詢加速技術
- ClickHouse 系列:Sampling 抽樣查詢與統計技術原理
- ClickHouse 系列:TTL 資料清理與儲存成本優化
- ClickHouse 系列:儲存政策(Storage Policies)與磁碟資源分層策略
- ClickHouse 系列:表格設計與儲存優化細節
- ClickHouse 系列:ClickHouse 系列:整合 Grafana 打造可視化監控
- ClickHouse 系列:查詢優化案例
- ClickHouse 系列:與 BI 工具整合(Power BI)
- ClickHouse 系列:ClickHouse Cloud 與自建部署的優劣比較
- ClickHouse 系列:資料庫安全性與權限管理(RBAC)實作
- ClickHouse 系列:Kubernetes 部署分散式架構
- ClickHouse 系列:從原始碼看 MergeTree 的六大核心機制